


Stable Diffusion 是一种深度学习文本到图像生成模型,它主要用于根据文本的描述产生详细图像,亦或者根据现有的图片生成相似的图片。 Stable Diffusion 是Stability AI的一个开源项目,可以在本地自己部署,训练出个人专属模型。下面以创盈芯M1A布署教程为例。

一、硬件准备:
创盈芯M1A AIPC,配置建议:
CPU:I9 12900H。
GPU:RTX3060M。
内存:16G及以上。
硬盘:固态盘 512G及以上。
stable diffusion因为是在本地部署,对显卡的要求比较高,如果经济能力可以的话,建议用性能更好的显卡。
二、、环境安装
1、python 环境安装
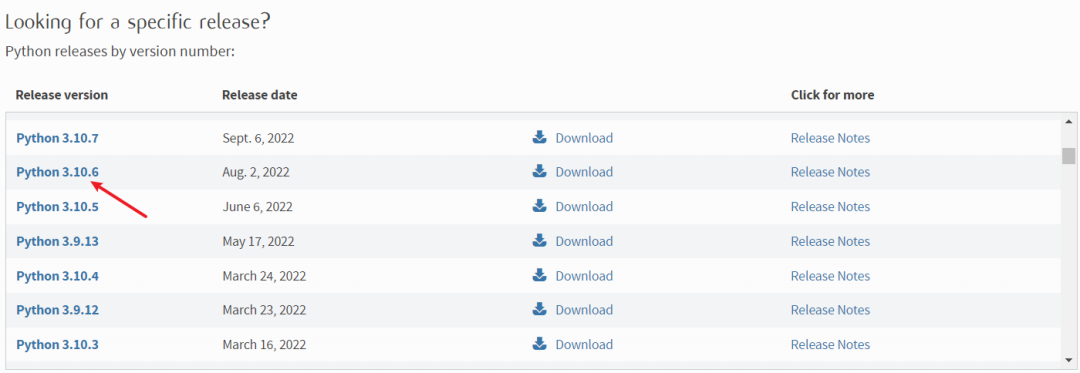
https://www.python.org/downloads/
下载Python3.10.6版本
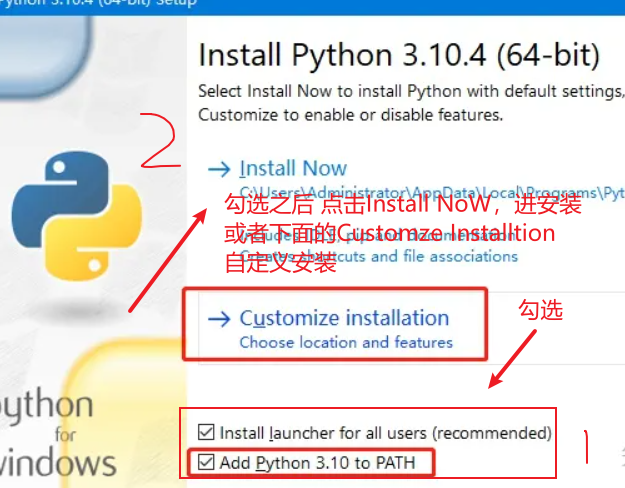
按下图操作之后直接默认安装就行
2、Git 安装【https://git-scm.com/】,进入官网直接下载安装即可。
三、项目安装
上面环境安装完毕之后,打开控制台命令框,输入如下命令,从Github拉取Stable Diffusion-webUI项目,存放到你的磁盘中。

命令如下
git https://github.com/AUTOMATIC1111/stable-diffusion-webui
拉取之后进入stable-diffusion-webui项目,双击webui.bat运行,此时会弹出命令框,静静等待安装依赖成功。
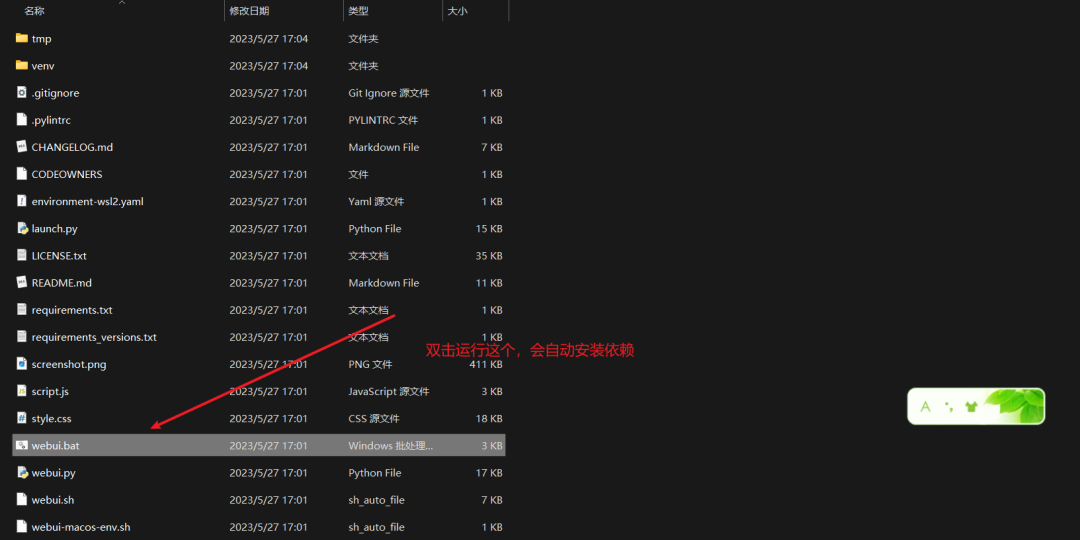
安装依赖中...
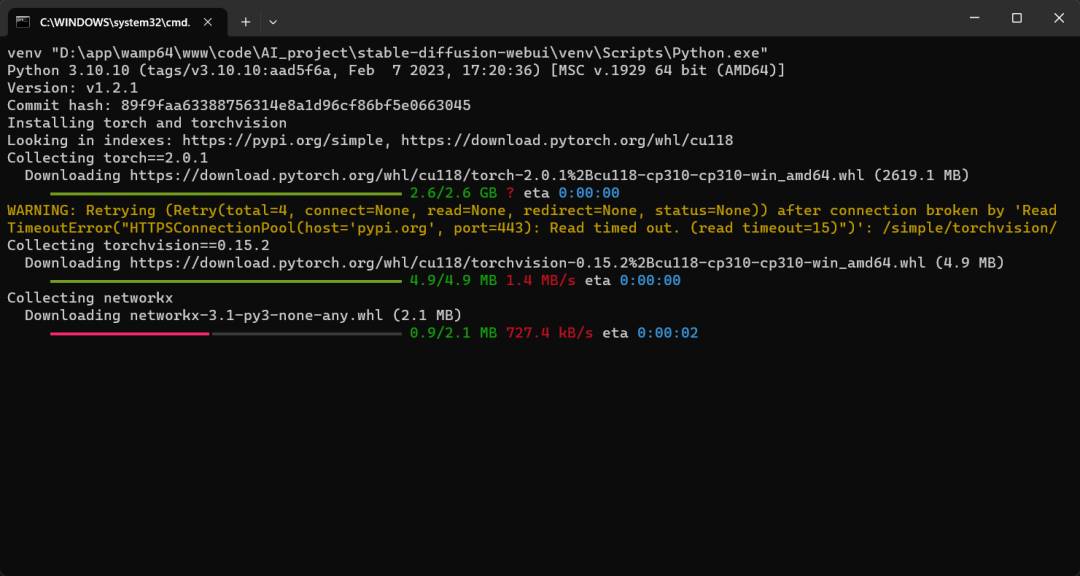
提示:如果依赖安装过程中出现错误,大概率是网络或者硬件不支持,安装时确保打开全局梯子。我安装依赖时,第一次也没成功,各种错误,有版本过低的、网络问题的错误,出错时会提示什么原因导致的错误,按它给出的提示一步一步解决即可。
依赖安装成功,复制提供的链接(http://127.0.0.1:7860),在浏览器打开即可,切记不要关闭命令框,关闭之后项目会暂停。
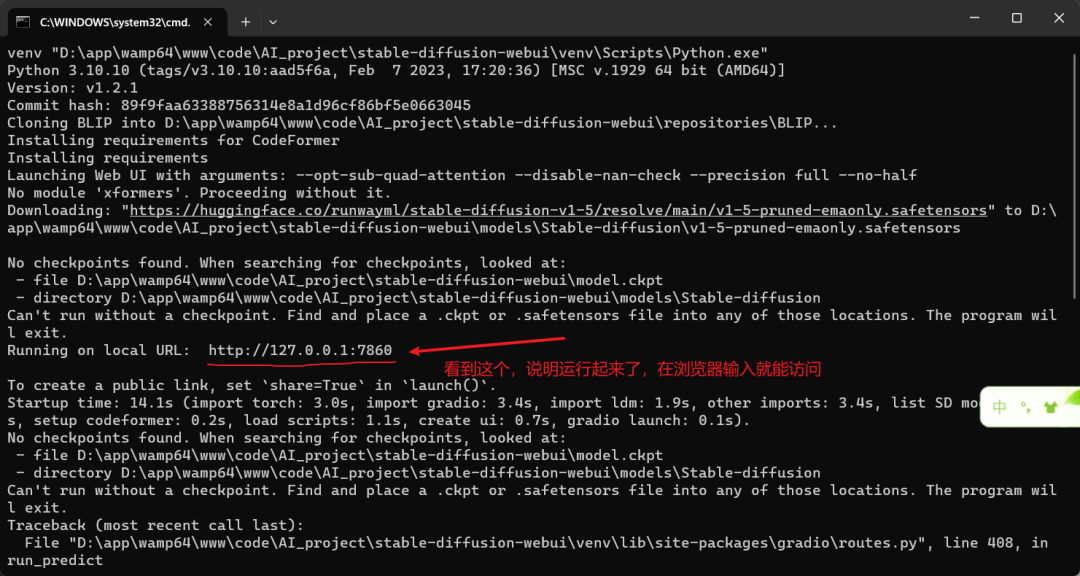
Stable Diffusion 运行起来的界面如下
如果看不懂英文,可以下载汉化包,比较简单,这个大家自行百度Stable Diffusion汉化,这里就不展开说了,如果实在不会,可以留言,下次出一个教程。
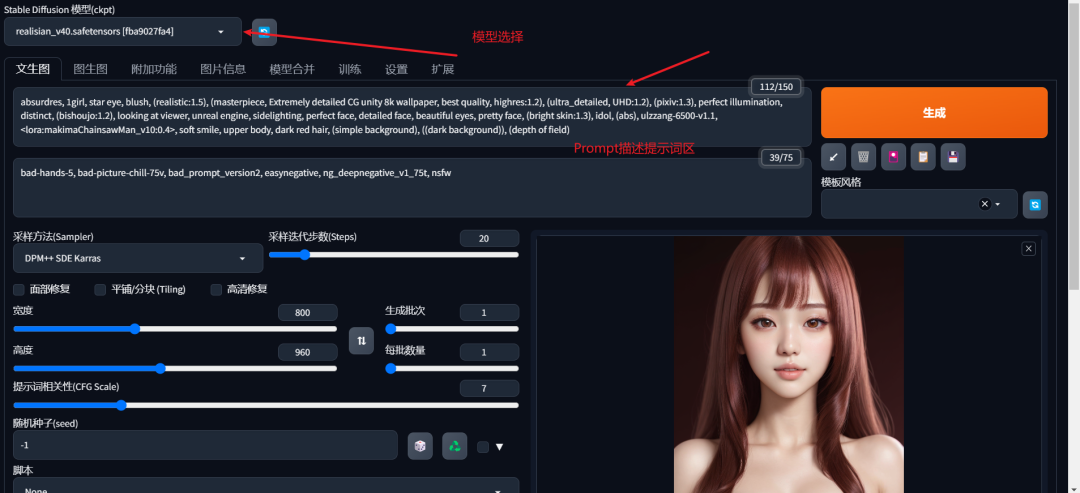
stable-diffusion-webUI功能很多,主要有两个常用的,分别是文生图(text2img)和图生图(img2img)
文生图: 根据提示词的描述生成相应的图片
图生图: 将一张图片提示词根据描述的特点生成另一张新的图片
左上角模型选择,大家可以去这个网站下载你喜欢的模型【https://civitai.com/】
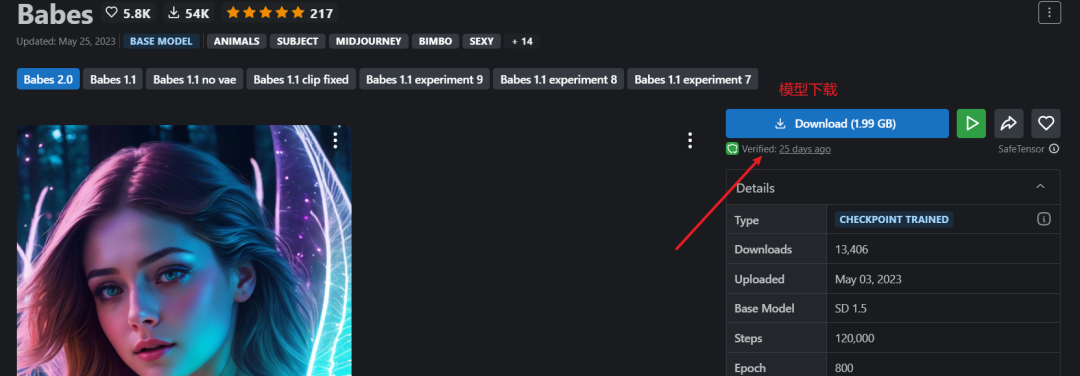
下载模型之后,把模型文件放到Stable Diffusion的model/Stable-diffusion里面,模型可以下载多个。
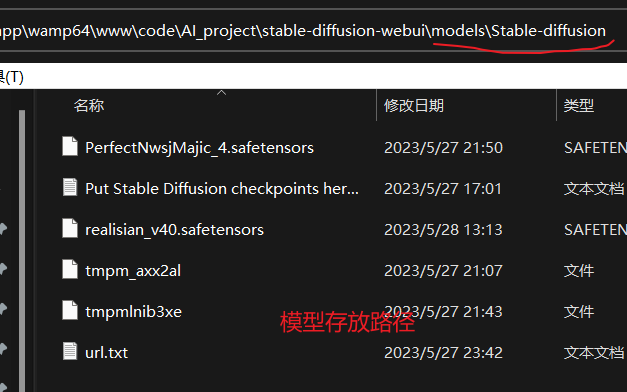
结语:
经过上述步骤,创盈芯M1已成功变身为高效AI艺术工作站!本地部署的Stable Diffusion不仅摆脱了云端服务的延迟与隐私顾虑,更能通过Apple Silicon芯片的统一内存架构实现低延迟创作。无论是为设计项目快速产出概念图,还是探索个人数字艺术的新边界,这台静音运行的AI创作引擎都将成为你的灵感倍增器。